Spring Boot에서 Elasticsearch 필드명을 Snake Case로 매핑하기

들어가며
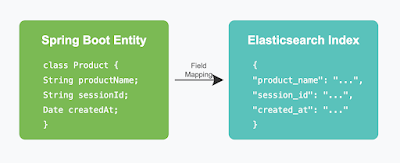
Spring Boot 환경에서 Elasticsearch를 사용할 때, Java 엔티티 클래스의 필드명이 자동으로 Elasticsearch 인덱스에 매핑되는 경우가 있습니다. 이때 Java의 camelCase 명명 규칙(예: modelName, sessionId)이 그대로 Elasticsearch 인덱스의 필드명으로 사용되어, 원하는 snake_case 형식(예: model_name, session_id)으로 매핑되지 않는 문제가 발생할 수 있습니다.
이 글에서는 이러한 문제를 해결하기 위한 다양한 방법과 각 방법의 장단점, 그리고 실제 적용 시 주의해야 할 점들을 상세히 알아보겠습니다.
1. @Field 어노테이션을 사용한 명시적 매핑
가장 직관적이고 명시적인 방법은 Spring Data Elasticsearch에서 제공하는
@Field
어노테이션을 사용하는 것입니다.
javaimport org.springframework.data.elasticsearch.annotations.Document; import org.springframework.data.elasticsearch.annotations.Field; import org.springframework.data.elasticsearch.annotations.FieldType; @Document(indexName = "products") public class Product { @Field(name = "product_id", type = FieldType.Keyword) private String productId; @Field(name = "product_name", type = FieldType.Text) private String productName; @Field(name = "created_at", type = FieldType.Date) private LocalDateTime createdAt; @Field(name = "description", type = FieldType.Text, analyzer = "standard") private String description; // getters and setters }
장점
- 필드별로 세밀한 제어가 가능
- 명시적이고 직관적인 매핑
- 타입과 분석기 등 추가 설정 가능
단점
- 모든 필드에 어노테이션을 추가해야 하는 번거로움
- 코드가 다소 장황해질 수 있음
2. Jackson 어노테이션을 사용한 클래스 레벨 매핑
전체 클래스의 필드명에 대해 일괄적으로 snake_case 변환을 적용하고 싶다면,
Jackson의
@JsonNaming
어노테이션을 사용할 수 있습니다.
javaimport com.fasterxml.jackson.databind.PropertyNaming; import com.fasterxml.jackson.databind.annotation.JsonNaming; @Document(indexName = "products") @JsonNaming(PropertyNaming.SnakeCaseStrategy.class) public class Product { private String productId; // product_id로 매핑 private String productName; // product_name으로 매핑 private LocalDateTime createdAt; // created_at으로 매핑 private String description; // description으로 매핑 // getters and setters }
장점
- 코드가 간결
- 클래스 전체에 일관된 네이밍 규칙 적용
- 추가 설정 없이 JSON 직렬화/역직렬화에도 동일한 규칙 적용
단점
- 필드별로 세밀한 제어가 어려움
- 특정 필드만 다른 네이밍 규칙을 적용하기 어려움
3. 전역 설정을 통한 매핑
애플리케이션 전체에 걸쳐 일관된 네이밍 규칙을 적용하고 싶다면, Elasticsearch 설정 클래스를 통해 전역 설정을 할 수 있습니다.
java@Configuration public class ElasticsearchConfig extends AbstractElasticsearchConfiguration { @Override public RestHighLevelClient elasticsearchClient() { ClientConfiguration clientConfiguration = ClientConfiguration.builder() .connectedTo("localhost:9200") .build(); return RestClients.create(clientConfiguration).rest(); } @Bean @Override public EntityMapper entityMapper() { ElasticsearchEntityMapper entityMapper = new ElasticsearchEntityMapper( elasticsearchMappingContext(), new DefaultConversionService() ); entityMapper.setObjectMapper(objectMapper()); return entityMapper; } @Bean public ObjectMapper objectMapper() { ObjectMapper mapper = new ObjectMapper(); mapper.setPropertyNamingStrategy(PropertyNamingStrategy.SNAKE_CASE); mapper.registerModule(new JavaTimeModule()); return mapper; } }
장점
- 애플리케이션 전체에 일관된 규칙 적용
- 설정의 중앙화
- 코드 중복 최소화
단점
- 유연성이 떨어짐
- 특정 도메인/엔티티만 다른 규칙을 적용하기 어려움
실제 적용 시 주의사항
1. 인덱스 재생성
필드명 매핑을 변경할 때는 기존 인덱스를 삭제하고 재생성해야 합니다. 다음은 인덱스를 재생성하는 유틸리티 메서드의 예시입니다.
java@Service public class IndexManagementService { private final ElasticsearchRestTemplate elasticsearchTemplate; public IndexManagementService(ElasticsearchRestTemplate elasticsearchTemplate) { this.elasticsearchTemplate = elasticsearchTemplate; } public void recreateIndex(Class<?> entityClass) { // 기존 인덱스 삭제 if (elasticsearchTemplate.indexExists(entityClass)) { elasticsearchTemplate.deleteIndex(entityClass); } // 새 인덱스 생성 elasticsearchTemplate.createIndex(entityClass); // 매핑 정보 적용 elasticsearchTemplate.putMapping(entityClass); } public void verifyMapping(Class<?> entityClass) { Map<String, Object> mapping = elasticsearchTemplate.getMapping(entityClass); System.out.println("Current mapping: " + mapping); } }
2. 데이터 마이그레이션
필드명이 변경되는 경우, 기존 데이터를 새로운 매핑에 맞게 마이그레이션해야 할 수 있습니다. 다음은 간단한 마이그레이션 예시입니다.
java@Service public class DataMigrationService { private final ElasticsearchRestTemplate elasticsearchTemplate; public DataMigrationService(ElasticsearchRestTemplate elasticsearchTemplate) { this.elasticsearchTemplate = elasticsearchTemplate; } public void migrateData(String oldIndex, String newIndex) { // 스크롤 API를 사용하여 대량의 데이터 처리 SearchScrollHits<Map> scrollHits = elasticsearchTemplate.searchScrollStart(1000, new NativeSearchQueryBuilder() .withQuery(QueryBuilders.matchAllQuery()) .build(), Map.class, oldIndex ); while (scrollHits.hasSearchHits()) { List<Map> documents = scrollHits.getSearchHits() .stream() .map(SearchHit::getContent) .collect(Collectors.toList()); // 새 인덱스에 데이터 벌크 삽입 elasticsearchTemplate.bulkIndex(documents, newIndex); // 다음 배치 가져오기 scrollHits = elasticsearchTemplate.searchScrollContinue(scrollHits.getScrollId(), 1000, Map.class, oldIndex ); } } }
3. 성능 고려사항
필드명 매핑 변경 시 고려해야 할 성능 관련 사항들:
- 인덱스 크기가 큰 경우, 재인덱싱에 상당한 시간이 소요될 수 있음
- 마이그레이션 중 서비스 중단을 최소화하기 위한 전략 필요
- 별칭(Alias)을 사용하여 무중단 마이그레이션 구현 가능
java@Service public class ZeroDowntimeMigrationService { private final ElasticsearchRestTemplate elasticsearchTemplate; public void performZeroDowntimeMigration(String indexName, Class<?> entityClass) { // 임시 인덱스 생성 String tempIndex = indexName + "_v2"; // 새 매핑으로 임시 인덱스 생성 elasticsearchTemplate.createIndex(tempIndex); elasticsearchTemplate.putMapping(entityClass); // 데이터 마이그레이션 migrateData(indexName, tempIndex); // 별칭 전환 updateAlias(indexName, tempIndex); } private void updateAlias(String aliasName, String newIndex) { IndicesAliasesRequest request = new IndicesAliasesRequest(); // 기존 별칭 제거 request.addAliasAction( new IndicesAliasesRequest.AliasActions(IndicesAliasesRequest.AliasActions.Type.REMOVE) .index("*") .alias(aliasName) ); // 새 별칭 추가 request.addAliasAction( new IndicesAliasesRequest.AliasActions(IndicesAliasesRequest.AliasActions.Type.ADD) .index(newIndex) .alias(aliasName) ); // 별칭 업데이트 실행 elasticsearchTemplate.getClient() .indices() .updateAliases(request, RequestOptions.DEFAULT); } }
권장 사항
-
명시적 매핑 선호
-
가능한 한
@Field어노테이션을 사용하여 명시적으로 매핑을 정의 - 문서화와 유지보수성 측면에서 유리
-
가능한 한
-
일관된 네이밍 규칙
- 프로젝트 전체에서 일관된 네이밍 규칙을 사용
- 가능하면 표준 컨벤션(예: snake_case)을 따르기
-
테스트 환경에서 검증
- 매핑 변경 전 테스트 환경에서 충분한 검증
- 마이그레이션 절차 리허설 수행
- 백업 및 롤백 계획
- 매핑 변경 전 데이터 백업
-
문제 발생 시 롤백 절차 준비
결론
Spring Boot와 Elasticsearch를 함께 사용할 때 필드명 매핑은 중요한 고려사항입니다. 위에서 설명한 여러 방법들 중에서 프로젝트의 요구사항과 상황에 맞는 최적의 방법을 선택하시기 바랍니다. 특히 프로덕션 환경에서는 데이터 안정성과 서비스 가용성을 최우선으로 고려하여 신중하게 접근해야 합니다.
위 내용들을 잘 활용하시면 Spring Boot와 Elasticsearch 환경에서 원하는 필드명 매핑을 효과적으로 구현하실 수 있을 것입니다.
Comments
Post a Comment